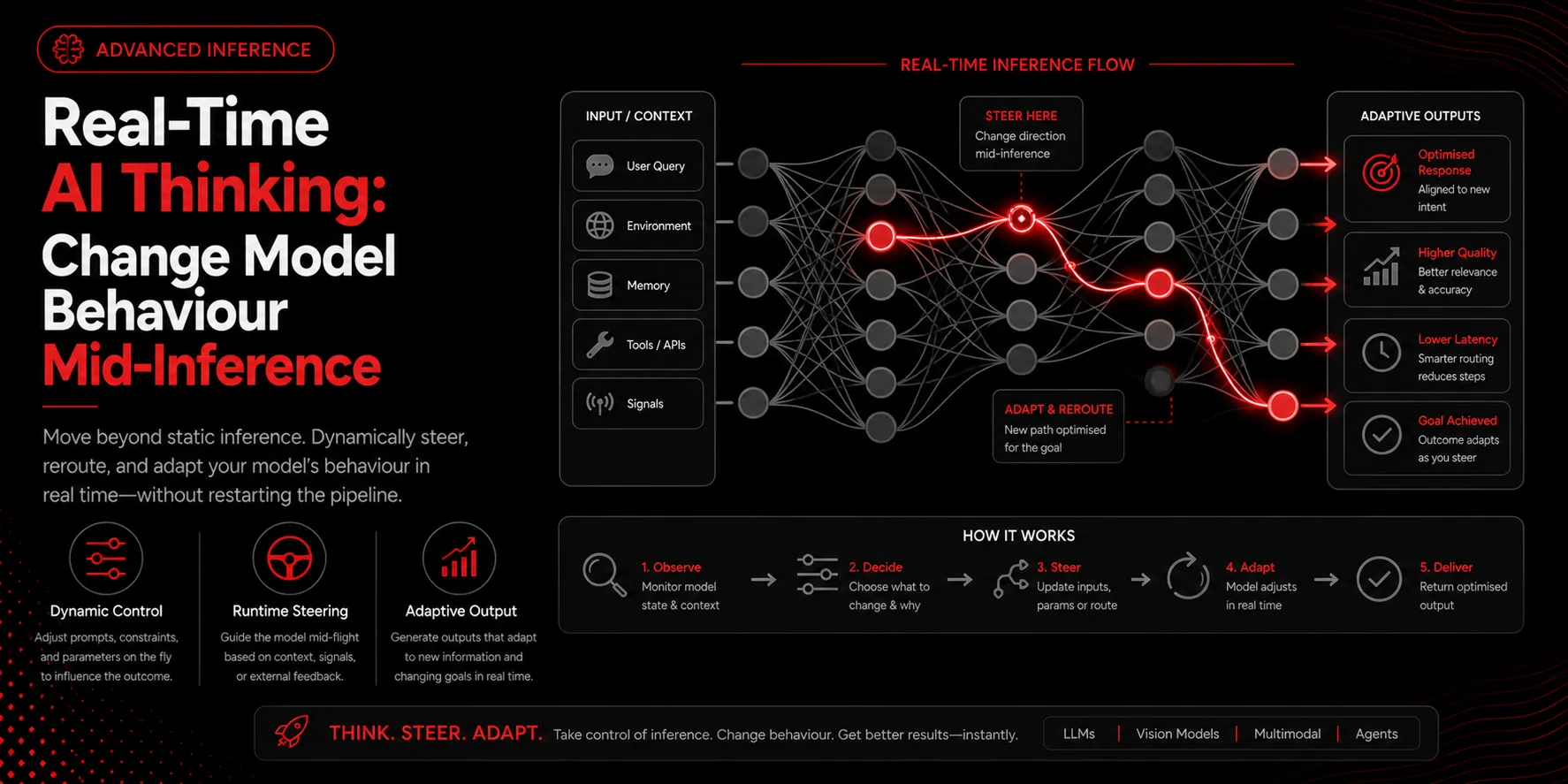
Large language models generate one token at a time, and that loop is a control point. You do not have to accept whatever the model produces; you can steer it as it thinks.
Generation is a loop you own
Each step, the model outputs logits over the vocabulary, you sample a token, and you feed it back. Because your code runs between steps, you can intervene every token. This is the foundation of real-time steering.
Control the logits
Before sampling, you can modify the logits. Masking forbids tokens, such as blocking unsafe words or forcing valid JSON. Biasing nudges the model toward or away from topics. Constrained decoding guarantees the output matches a grammar or schema.
Adapt sampling dynamically
Temperature and top-p do not have to be fixed for a whole response. You can start focused for a factual opening and loosen for creative continuation, or tighten sampling when confidence drops.
Stop when you have enough
Dynamic stopping criteria end generation the moment the answer is complete, a stop sequence appears, or a confidence threshold is met. This saves compute and latency versus always running to a fixed length.
Interrupt and redirect
In an agent loop, you can halt generation when a tool call is detected, run the tool, and resume with new context. The model’s behaviour changes mid-stream in response to real-world results.
Key takeaways
- Generation is a per-token loop you can intervene in
- Use logit masking and biasing to constrain output
- Vary sampling parameters within a single response
- Apply dynamic stopping to save compute and latency
- Interrupt and resume to build adaptive agents


